新知榜官方账号
2023-11-10 16:05:30
在最近的研究论文《CodeFusion:APre-trainedDiffusionModelforCodeGeneration》中,微软无意中揭示了一个关于ChatGPT的引人注目的细节:这个模型实际上拥有200亿参数。这个发现迅速在全球科技界引起了轰动,因为参数数量在一定程度上象征着模型的复杂性和处理信息的能力。ChatGPT的成功不仅为大型模型树立了新的标准,也为人工智能的未来发展指明了方向。
自从ChatGPT去年11月面世以来,中国国内便掀起了一场大模型的竞赛。各大企业和研究机构纷纷投入巨资,希望在这一领域实现突破。然而,尽管中国的大模型如文心一言、清华智谱等在参数规模上达到了65B和130B,但在性能上仍未能超越GPT-3.5的20B标准。这背后的原因值得我们深入探讨。
在探讨中美科技差距的根源时,不得不提到制度环境与政策导向的影响。中国的审查制度和技术监管,在保证社会稳定和文化传承方面发挥了作用,但同时也可能限制了科技企业的创新动力和国际竞争力。在全球化的科技竞赛中,这种制度性差异可能导致中国企业在开放性和创新速度上处于劣势,从而影响其在人工智能等前沿科技领域的全球布局。
技术基础和研发投入是衡量一个国家科技实力的重要指标。在AI底层技术、芯片制造和大型语言模型的研发上,中国与美国之间的差距是科技竞争的关键。美国在这些领域的深厚积累和持续投入,使其在全球科技舞台上占据了领先地位。相比之下,中国虽然在短时间内取得了显著进步,但在关键技术的原创性研发和核心竞争力上仍需加大力度。
人才是推动科技创新的核心力量。当前,顶尖AI人才的流失,特别是流向美国,对中国在高端技术研发的人力资源基础构成了挑战。根据智库MacroPolo的数据,尽管中国培养了大量的AI研究人员,但许多人选择在美国发展,这不仅减少了国内的高端人才储备,也间接加强了美国在AI领域的领先地位。
以清华智谱为例:该模型在参数规模上达到了130B,但在实际应用中,其生成文本的准确性和流畅性仍然无法与GPT-3.5相媲美。这可能是因为缺乏足够多样化和高质量的训练数据,或者是因为模型训练过程中的优化算法不够先进。例如,在自然语言理解任务中,清华智谱可能在处理复杂的语境和隐含意义时表现不佳,这表明模型在理解深层语义关系方面还有提升的空间。
以百度的文心一言为例:文心一言是百度推出的大型语言模型,其在多项自然语言处理任务上表现出色。然而,与GPT-4相比,文心一言在跨领域适应性和创新性文本生成方面仍有差距。例如,在生成技术文章或诗歌这类需要高度创造力的任务上,文心一言生成的文本可能缺乏GPT-4那样的深度和新颖性。这可能是因为模型训练时使用的数据集在多样性和复杂性上不足,或者是因为模型的架构和训练方法未能充分捕捉到语言的深层次创造力。
以科大讯飞的星火为例:科大讯飞是中国领先的语音识别和自然语言处理技术公司,其星火模型在语音识别和语音合成领域取得了显著成就。但是,当涉及到与GPT-4相比较的复杂文本理解和生成任务时,星火模型可能在理解上下文的连贯性和生成语言的多样性方面显得不足。例如,在模拟对话或生成长篇故事的任务中,星火模型可能无法像GPT-4那样连贯地维持话题,或者在生成具有特定风格的文本时缺乏一致性。这可能反映了模型在长期依赖记忆和风格适应方面的局限性。
在深入探讨中国在人工智能领域的发展时,我们不仅见证了中国大型语言模型在规模扩张和特定任务执行上的显著进步,但与GPT-4等全球领先模型的对比揭示了在创新性、适应性和复杂文本处理能力方面的明显差距。这种差距不禁让我们回想起历史上的“李约瑟之问”,推动我们反思在制度环境、技术基础和人才培养等方面的深层次原因。中国的科技竞赛不仅是对模型规模的追求,更是对高质量模型训练、数据集多样性和算法创新的考验。面对全球化的科技竞争,中国必须进行全面的制度和思想自我创新,通过开放合作,才能实现在人工智能领域的全面突破,为全球的科技进步贡献中国智慧。
 微信扫码咨询
微信扫码咨询  相关工具
相关工具
相关文章
相关快讯
推荐

中国首款3A游戏上线,《黑神话:悟空》出圈!
2024-08-21 13:46
盘点15款AI配音工具,短视频配音有救了!
2024-08-12 17:11

短视频文案没创意?10大AI写作工具来帮你!
2024-08-05 16:23

Midjourney发布V6.1版本,我已分不清AI和现实了!
2024-08-01 15:03

我发现了一款国产AI绘画神器,免费易上手!
2024-07-25 16:40
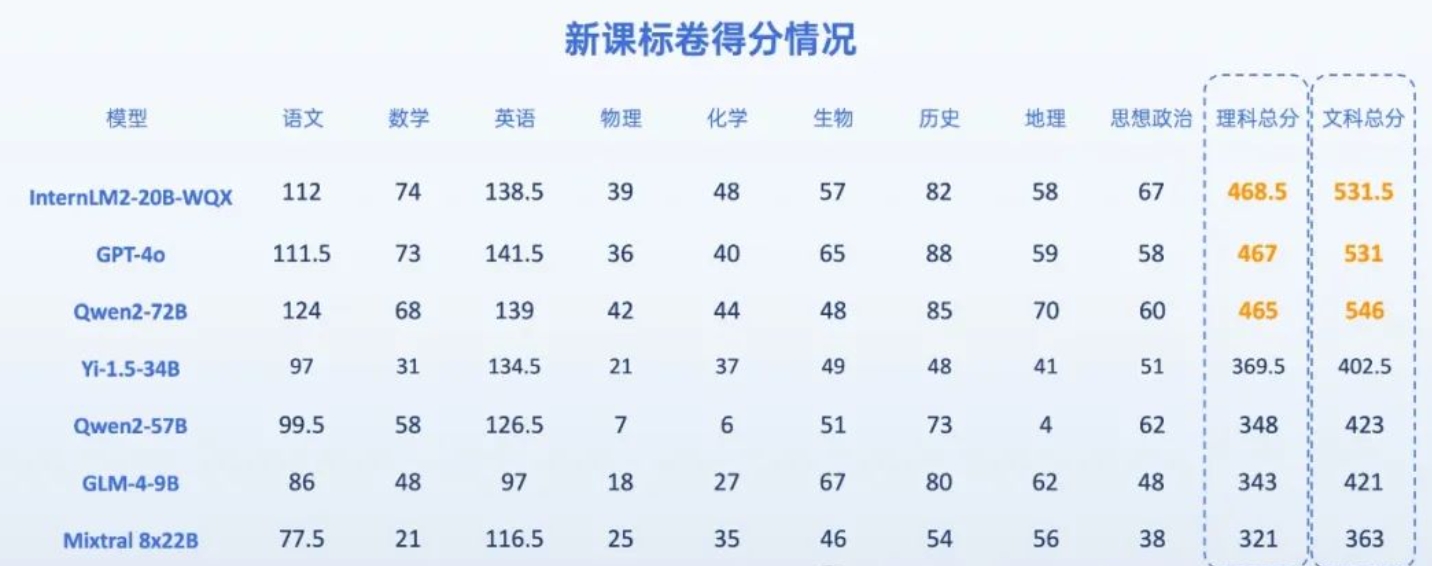
7位AI考生做今年高考题,能过一本线吗?
2024-07-19 17:17

世界上第一所AI学校来了,80亿人只需要1位老师?
2024-07-18 17:12

Sora首部AI广告片上线,广告从业者危险了!
2024-06-27 13:44

OpenAI与中国说拜拜,国产AI如何接棒?
2024-06-26 15:18

人与AI会产生爱情吗,专家发话了!
2024-06-17 17:28
Copyright © 2017-2024 蜀ICP备18012294号-1
成都新知榜文化传播有限公司 版权所有



