新知榜官方账号
2023-08-05 16:04:45
如今,国内市场上已有100多款大模型产品。但如何挑选出一款最适合自己的大模型,成为企业和机构新的难题。业界亟需一些权威评测,作为客户选择大模型产品的“指南针”。
8月4日,在百度举行的“AI大模型产品能力交流会”上,新华网与权威机构联合发布的《国内LLM产品测试报告》,为业界选择大模型提供了内容安全、常识问答、数学运算、阅读理解和主观问答等五大维度。
新华网测试报告对文心一言、GPT-3.5等四大知名大模型进行评测,结果显示,百度文心一言综合得分第一。文心一言是百度自主研制的知识增强大语言模型,具备知识增强、检索增强和对话增强等技术优势。内容价值是选择大模型的重要考虑因素。在新华网的评测报告中,有两大关于内容的维度。一是内容安全问答,包含了意识形态、非法涉黄等多项维度,二是常识问答,涵盖有中国文化、历史、地理和生活等常识知识。
新华网物联网技术总监葛振斌表示,“大模型生成的内容必须符合当地法律和社会道德要求。可以说,各个国家都需要‘更适合自己历史文化’的大语言模型。”
新华网物联网技术总监葛振斌认为,评测大模型有5项维度非常重要:一是把控生成内容安全性的能力,二是常识推断计算的能力,三是对长文本的语义理解能力,四是数学运算及数学推理能力,五是主观思维能力。新华网评测报告显示,文心一言因中文搜索引擎和算法模型优势,在安全、常识、数学、阅读等方面优势明显。在五个维度上的得分计算均值,文心一言的综合得分为94.7分,排名第一,高于GPT-3.5的76.9分。
如今,参考权威机构评测成为客户选择大模型的一个重要方式。创业者和开发者以及中小企业,其实不需要从0到1的打造自己的大模型,可以基于文心大模型打造智能应用,避免重复造轮子,把精力放在自己擅长的创新上。谁先做出来满足用户需求的应用,谁就抢占了发展先机。
百度2019年推出文心大模型1.0,今年5月份升级到3.5版本。通过飞桨深度学习平台与文心大模型的协同优化,文心大模型3.5实现了基础模型升级、精调技术创新、知识点增强、逻辑推理增强、插件机制等,模型效果提升50%,训练速度提升2倍,推理速度提升30倍。目前百度文心大模型已拥有中国最大的产业落地规模,超过15万家企业申请文心一言内测,其中有超300家生态伙伴在400多个具体场景取得测试成效,覆盖办公提效、知识管理、智能客服、智能营销等领域,联合国家电网、浦发银行、泰康、吉利等企业,联合发布了11个行业大模型。
 微信扫码咨询
微信扫码咨询  相关工具
相关工具
相关文章
相关快讯
推荐

中国首款3A游戏上线,《黑神话:悟空》出圈!
2024-08-21 13:46
盘点15款AI配音工具,短视频配音有救了!
2024-08-12 17:11

短视频文案没创意?10大AI写作工具来帮你!
2024-08-05 16:23

Midjourney发布V6.1版本,我已分不清AI和现实了!
2024-08-01 15:03

我发现了一款国产AI绘画神器,免费易上手!
2024-07-25 16:40
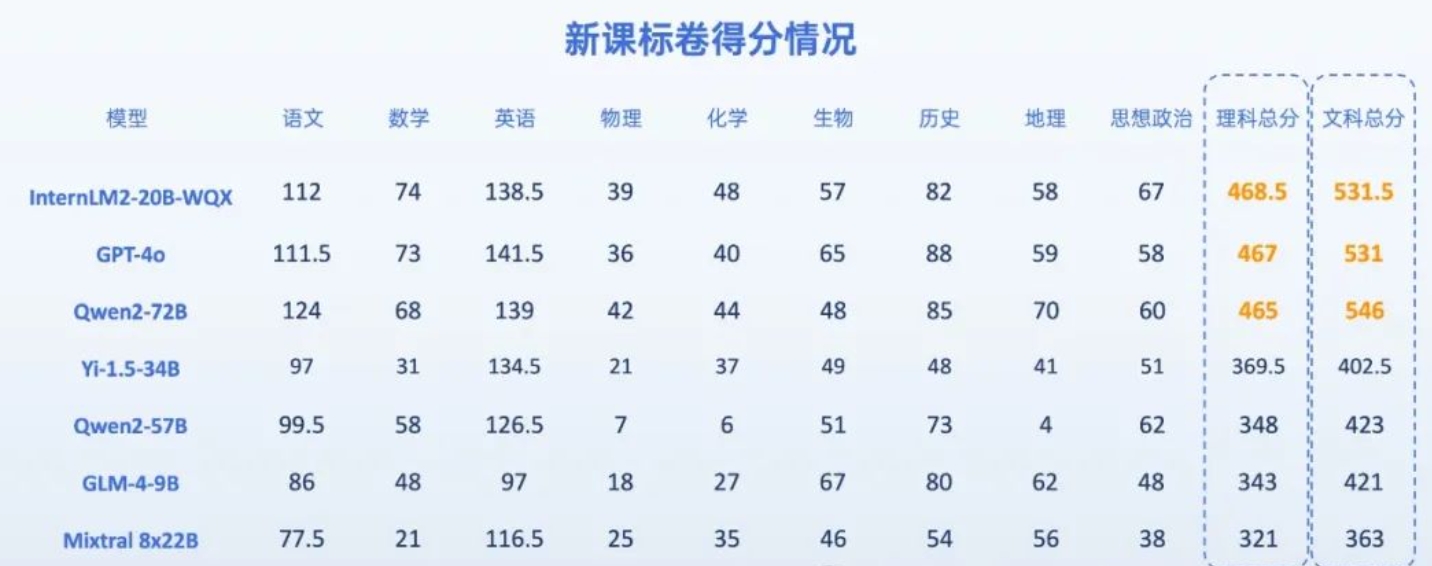
7位AI考生做今年高考题,能过一本线吗?
2024-07-19 17:17

世界上第一所AI学校来了,80亿人只需要1位老师?
2024-07-18 17:12

Sora首部AI广告片上线,广告从业者危险了!
2024-06-27 13:44

OpenAI与中国说拜拜,国产AI如何接棒?
2024-06-26 15:18

人与AI会产生爱情吗,专家发话了!
2024-06-17 17:28
Copyright © 2017-2024 蜀ICP备18012294号-1
成都新知榜文化传播有限公司 版权所有



