新知榜官方账号
2023-07-02 10:46:49
谷歌最近发布了最新翻译创新技术,这些技术提升了谷歌翻译的用户体验。目前,谷歌翻译可支持108种语言,平均每天翻译1500亿个单词。谷歌翻译最早亮相于2006年,在过去的13年间,翻译水平有了重大飞跃。
谷歌表示,其翻译突破并不是由单一技术推动的,而是针对低资源语言、高资源语言、总体质量、推理速度等一系列技术组合的突破。在2019年5月到2020年5月之间,根据人工评估和BLEU(基于翻译系统翻译和人工参考翻译之间相似性的衡量标准),谷歌翻译在所有语言中平均提高了5分以上,在50种语料资源最少的语言中平均提高了7分以上。
在这系列技术突破中,谷歌首先提到了混合模型和数据挖掘器。混合模型指的是由Transformer编码器和递归神经网络(RNN)解码器构成的模型。在机器翻译中,编码器通常将单词和短语编码为内部表征,解码器将其生成为所需要的语言文本。谷歌的研究人员在2017年称首次提出,翻译质量的提高主要依靠编码器。谷歌团队称这可能是因为RNN和Transformer都设计为处理有序数据序列,但Transformers并不需要按顺序处理序列。换句话说,如果所讨论的数据是自然语言,则Transformer无需在处理结尾之前先处理句子的开头。尽管如此,RNN解码器在推理时间上仍然比Transformer中的解码器要“快得多”。谷歌翻译团队认识到这一点,于是在将RNN解码器与Transformer编码器耦合之前,对RNN解码器进行了优化,以创建低延迟、质量及稳定性均比此前所使用的RNN神经机器翻译模型更胜一筹的混合模型。
除了新颖的混合模型体系结构之外,谷歌还升级了爬虫工具,爬虫工具可以从数以百万计的示例翻译中收集编译训练数据。升级后,谷歌嵌入了14种大语言对,而不是单纯基于字典数据。也就是说它是使用实数向量来表示单词和短语,更多地聚焦于精确性(检索数据中的相关数据部分),而非检索(实际检索的相关数据总量)。产出效果方面,谷歌说这使得该数据挖掘器提取到的句子数量平均增加了29%。
谷歌翻译性能提升的另一个技术突破来自更好地处理训练数据中的“噪声”。“噪声”即嘈杂的数据,因含有大量无法正确理解或解释的信息数据,从而会损害语料资源丰富的语言翻译。因此谷歌翻译团队部署了一个系统,该系统使用经过训练的模型为翻译示例分配分数,进而筛选出“纯净”的数据。实际上,这些模型一开始基于所有的数据进行训练,然后逐渐基于更小、更纯净的数据子集进行训练,这种方法在人工智能研究领域被称为课程学习。对于机器翻译来说,传统上依赖于源语言和目标语言中成对句子的语料统计。对于资源较少的语言,谷歌在谷歌翻译中采用了一个回译机制,来强化并行训练数据,即语言中的每个句子都与其译文相配对。在该机制中,训练数据与合成的并行数据自动对齐,目标文本为自然语言,而源文本则由神经翻译模型生成。结果是,谷歌翻译充分利用更丰富的单语文本数据来训练模型,谷歌称这对提高翻译流畅性特别有帮助。
谷歌称,自2010年以来,翻译质量每年都在提高,但是机器翻译绝不是翻译问题的“终结者”。谷歌承认,即使是增强后的模型也容易出错,包括将一种语言的不同方言混合在一起,产生过多的直译,以及在特定主题、非正式或口语上的表现不佳。谷歌尝试用不同的方法来解决上述的问题。公司曾发布一项计划旨在招募志愿者,通过检查翻译单词和短语是否正确来帮助提高低资源语言的翻译性能。今年2月份,谷歌翻译与新兴的机器学习技术相结合后就完成了进步,他们提供了仅有7500万人使用的五种语言翻译,例如Kinyarwanda(卢旺达语),Odia(奥里亚语),Tatar(鞑靼语),Turkmen(土库曼语)和Uyghur(维吾尔语)。
 微信扫码咨询
微信扫码咨询  相关工具
相关工具
相关文章
推荐

中国首款3A游戏上线,《黑神话:悟空》出圈!
2024-08-21 13:46
盘点15款AI配音工具,短视频配音有救了!
2024-08-12 17:11

短视频文案没创意?10大AI写作工具来帮你!
2024-08-05 16:23

Midjourney发布V6.1版本,我已分不清AI和现实了!
2024-08-01 15:03

我发现了一款国产AI绘画神器,免费易上手!
2024-07-25 16:40
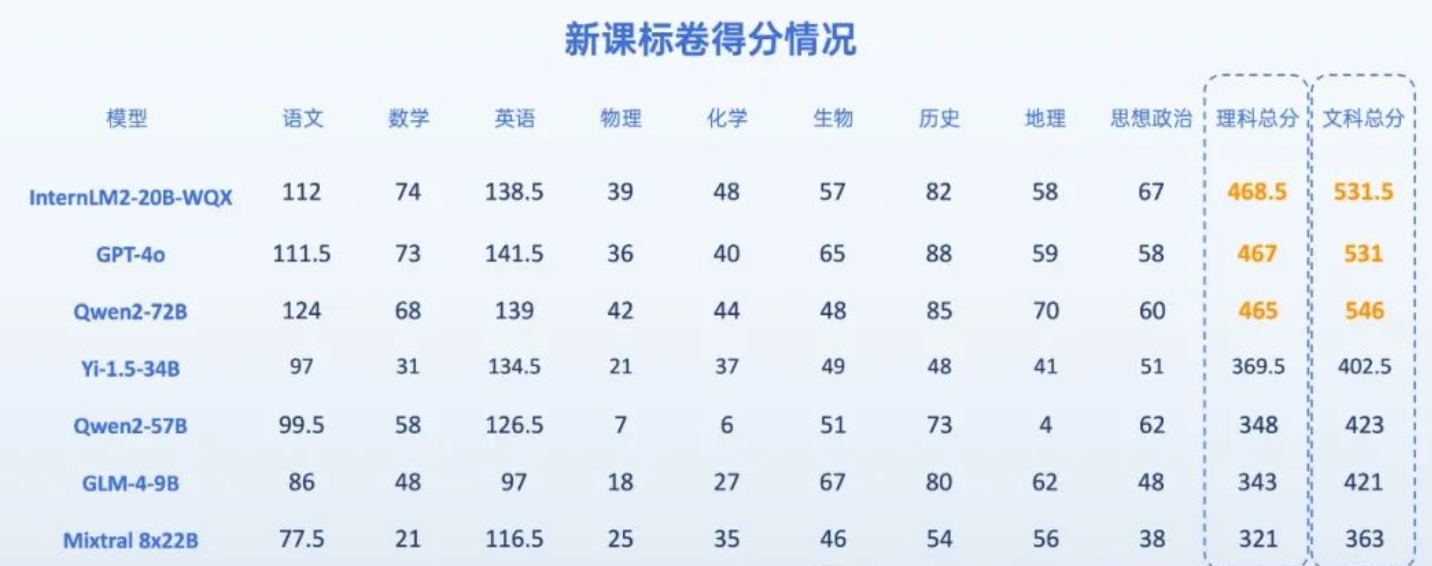
7位AI考生做今年高考题,能过一本线吗?
2024-07-19 17:17

世界上第一所AI学校来了,80亿人只需要1位老师?
2024-07-18 17:12

Sora首部AI广告片上线,广告从业者危险了!
2024-06-27 13:44

OpenAI与中国说拜拜,国产AI如何接棒?
2024-06-26 15:18

人与AI会产生爱情吗,专家发话了!
2024-06-17 17:28
Copyright © 2017-2024 蜀ICP备18012294号-1
成都新知榜文化传播有限公司 版权所有



