新知榜官方账号
2023-11-11 02:02:12
国内的AI语言文字处理模型与国外的ChatGPT在写作方式、内容丰富度等方面存在差距。这种差距可能来自以下技术因素:
为了缩小国内与国外AI语言文字处理模型的差距,需要持续的创新和国际合作。
 微信扫码咨询
微信扫码咨询  相关工具
相关工具
相关文章
相关快讯
推荐

中国首款3A游戏上线,《黑神话:悟空》出圈!
2024-08-21 13:46

盘点15款AI配音工具,短视频配音有救了!
2024-08-12 17:11

短视频文案没创意?10大AI写作工具来帮你!
2024-08-05 16:23

Midjourney发布V6.1版本,我已分不清AI和现实了!
2024-08-01 15:03

我发现了一款国产AI绘画神器,免费易上手!
2024-07-25 16:40
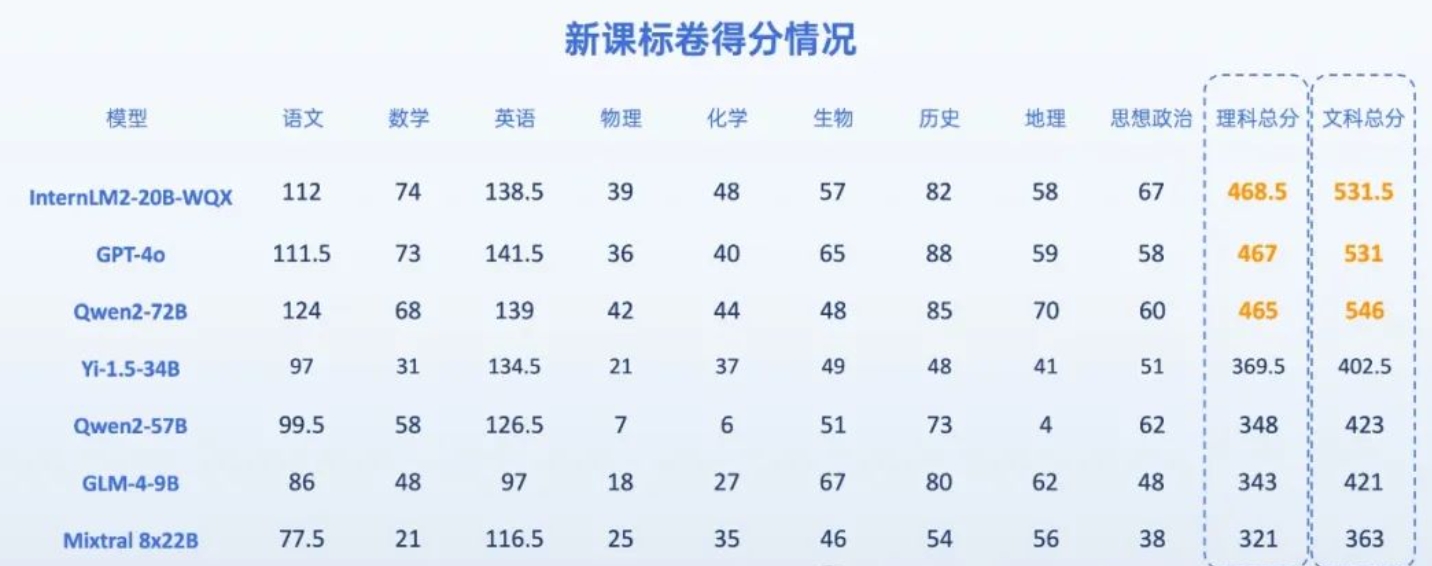
7位AI考生做今年高考题,能过一本线吗?
2024-07-19 17:17

世界上第一所AI学校来了,80亿人只需要1位老师?
2024-07-18 17:12

Sora首部AI广告片上线,广告从业者危险了!
2024-06-27 13:44

OpenAI与中国说拜拜,国产AI如何接棒?
2024-06-26 15:18

人与AI会产生爱情吗,专家发话了!
2024-06-17 17:28
Copyright © 2017-2024 蜀ICP备18012294号-1
成都新知榜文化传播有限公司 版权所有



