新知榜官方账号
2023-11-04 16:34:16
语音到语音翻译(S2ST)是打破世界各地人们之间语言障碍的关键。自动S2ST系统通常由一系列语音识别、机器翻译和语音合成子系统组成。然而,这种级联系统可能会遭受更长的延迟、信息丢失(尤其是副语言和非语言信息)以及子系统之间的复合错误。
2019年,Google推出了Translatotron,这是有史以来第一个能够直接在两种语言之间翻译语音的模型。这种直接的S2ST模型能够有效地进行端到端的训练,并且还具有在翻译语音中保留源说话者的声音(非语言信息)的独特能力。然而,尽管它能够以高保真度生成听起来自然的翻译语音,但与强大的基线级联S2ST系统(例如,由直接语音到文本翻译模型[1,2]和Tacotron2组成)相比,它的表现仍然不佳。TTS模型。
在“Translatotron2:RobustdirectSpeech-to-speechtranslation”中,Google描述了Translatotron的改进版本,该版本显着提高了性能,同时还应用了一种将源说话者的声音转换为翻译语音的新方法。即使输入语音包含多个说话者轮流说话,修改后的语音转移方法也是成功的,同时也减少了误用的可能性并更好地符合Google的AI原则。在三个不同语料库上的实验一致表明,Translatotron2在翻译质量、语音自然度和语音鲁棒性方面大大优于原始Translatotron。
Translatotron2由四个主要组件组成:语音编码器、目标音素解码器、目标语音合成器和将它们连接在一起的注意力模块。编码器、注意力模块和解码器的组合类似于典型的直接语音到文本翻译(ST)模型。合成器以解码器和注意力的输出为条件。
Translatotron和Translatotron2之间的三个新变化是提高性能的关键因素:
Translatotron2在Google衡量的各个方面都大大优于原始Translatotron:更高的翻译质量(由BLEU衡量,越高越好)、语音自然度(由MOS衡量,越高越好)和语音鲁棒性(由UDR衡量,越低越好)。它在更难的Fisher语料库中表现尤为出色。在多语言设置上的性能,Translatotron2再次大幅超越了原来的Translatotron。
 微信扫码咨询
微信扫码咨询  相关工具
相关工具
相关文章
推荐

中国首款3A游戏上线,《黑神话:悟空》出圈!
2024-08-21 13:46
盘点15款AI配音工具,短视频配音有救了!
2024-08-12 17:11

短视频文案没创意?10大AI写作工具来帮你!
2024-08-05 16:23

Midjourney发布V6.1版本,我已分不清AI和现实了!
2024-08-01 15:03

我发现了一款国产AI绘画神器,免费易上手!
2024-07-25 16:40
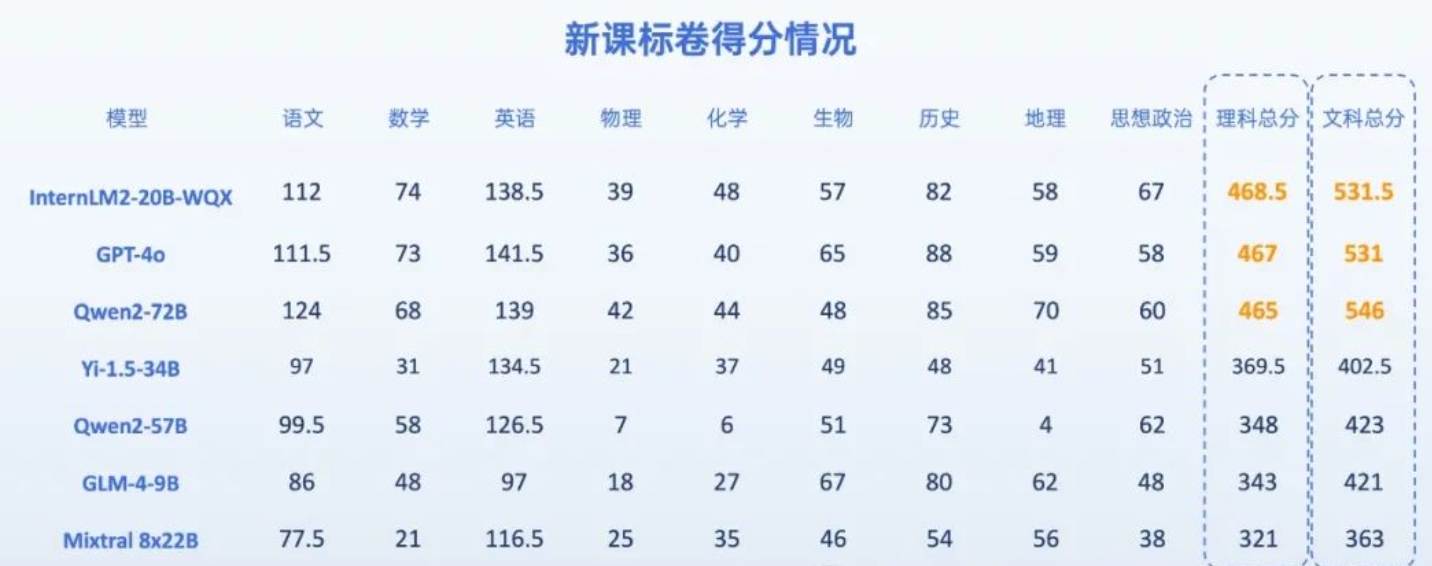
7位AI考生做今年高考题,能过一本线吗?
2024-07-19 17:17

世界上第一所AI学校来了,80亿人只需要1位老师?
2024-07-18 17:12

Sora首部AI广告片上线,广告从业者危险了!
2024-06-27 13:44

OpenAI与中国说拜拜,国产AI如何接棒?
2024-06-26 15:18

人与AI会产生爱情吗,专家发话了!
2024-06-17 17:28
Copyright © 2017-2024 蜀ICP备18012294号-1
成都新知榜文化传播有限公司 版权所有



