新知榜官方账号
2023-07-03 10:12:23
本文对三大语言模型Bard、ChatGPT、文心一言的能力进行了测试比较,从文学创作、逻辑推理、中文理解等方面进行了评估。
在互相评价方面,Bard的回答较为客观,ChatGPT的英文表述好于Bard,文心一言理解到了同类型小说,但未呈现阶级差异。
在文学创作方面,Bard和ChatGPT还是依旧脱不了原著的影子,而文心一言理解到了同类型小说,但缺少阶级差异。
在取名和宣传语方面,ChatGPT的“麻辣香坊”是唯一一个取了名字且写了广告词的大模型。
在逻辑推理方面,Bard和ChatGPT认为题目有问题,而文心一言没有完全理解题目意思。
在写代码方面,Bard和文心一言生成的代码是有问题的,而ChatGPT给出了正确的答案。
在中文理解能力方面,文心一言的确是遥遥领先的,但每一次生成的答案都不相同。
在理解哲学问题方面,三大模型都没有逻辑问题,并且对“无限”和“有限”做出了解释。
最后,三大模型更像是作为辅助工具而存在。
 微信扫码咨询
微信扫码咨询  相关工具
相关工具
相关文章
相关快讯
推荐

中国首款3A游戏上线,《黑神话:悟空》出圈!
2024-08-21 13:46
盘点15款AI配音工具,短视频配音有救了!
2024-08-12 17:11

短视频文案没创意?10大AI写作工具来帮你!
2024-08-05 16:23

Midjourney发布V6.1版本,我已分不清AI和现实了!
2024-08-01 15:03

我发现了一款国产AI绘画神器,免费易上手!
2024-07-25 16:40
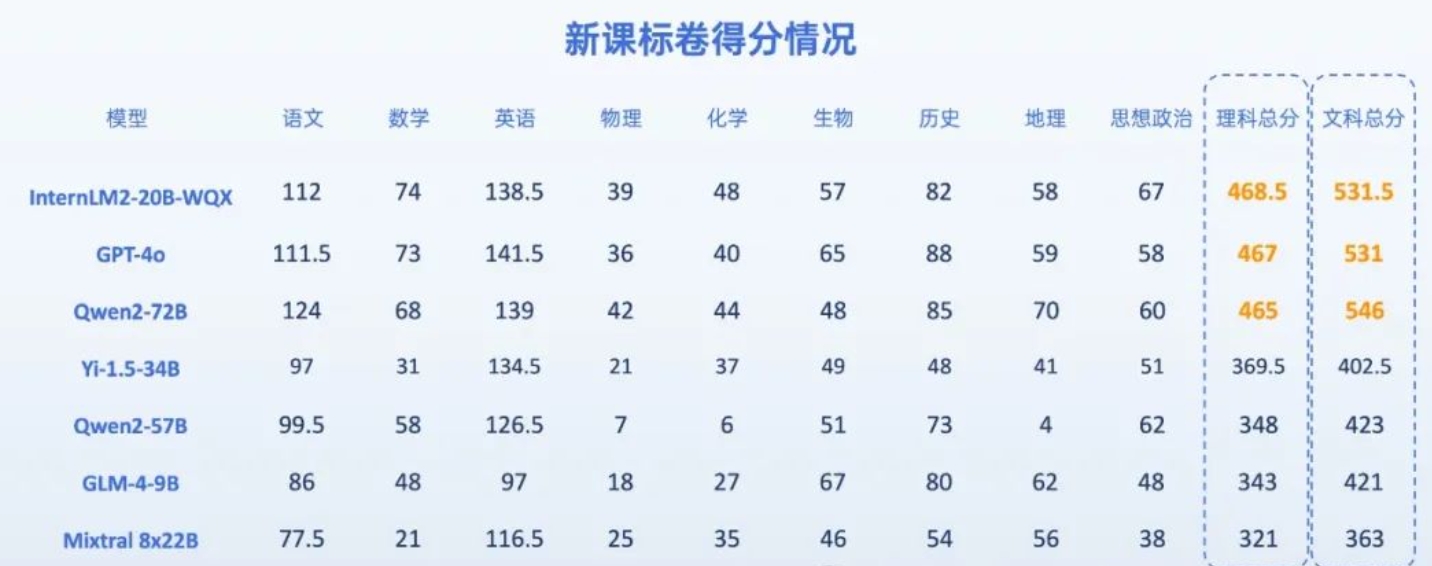
7位AI考生做今年高考题,能过一本线吗?
2024-07-19 17:17

世界上第一所AI学校来了,80亿人只需要1位老师?
2024-07-18 17:12

Sora首部AI广告片上线,广告从业者危险了!
2024-06-27 13:44

OpenAI与中国说拜拜,国产AI如何接棒?
2024-06-26 15:18

人与AI会产生爱情吗,专家发话了!
2024-06-17 17:28
Copyright © 2017-2024 蜀ICP备18012294号-1
成都新知榜文化传播有限公司 版权所有



