新知榜官方账号
2023-09-17 03:44:59
自然语言是人类独有的智慧结晶。自然语言处理(Natural Language Processing,NLP)是计算机科学领域与人工智能领域中的一个重要方向,旨在研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。用自然语言与计算机进行通信,有着十分重要的实际应用意义,也有着革命性的理论意义。由于理解自然语言,需要关于外在世界的广泛知识以及运用操作这些知识的能力,所以自然语言处理,也被视为解决人工智能完备(AI-complete)的核心问题之一。对自然语言处理的研究也是充满魅力和挑战的。
本文总结了自然语言处理领域近15年来的8大里程碑事件,涵盖了神经网络、语言模型、注意力机制、序列到序列模型、基于记忆的神经网络以及预训练的语言模型等方面的重要进展。
语言模型解决的是在给定已出现词语的文本中,预测下一个单词的任务。这可以算是最简单的语言处理任务,但却有许多具体的实际应用,例如智能键盘、电子邮件回复建议等。当然,语言模型的历史由来已久。经典的方法基于n-grams模型(利用前面n个词语预测下一个单词),并利用平滑操作处理不可见的n-grams。第一个神经语言模型,前馈神经网络(feed-forward neural network),是Bengio等人于2001年提出的。这个模型以某词语之前出现的n个词语作为输入向量。近年来,用于构建语言模型的前馈神经网络已经被循环神经网络(RNNs)和长短期记忆神经网络(LSTMs)取代。虽然后来提出的许多新模型在经典的LSTM上进行了扩展,但它仍然是强有力的基础模型。
多任务学习是在多个任务下训练的模型之间共享参数的方法,在神经网络中可以通过捆绑不同层的权重轻松实现。多任务学习的思想在1993年由Rich Caruana首次提出,并应用于道路追踪和肺炎预测。多任务学习鼓励模型学习对多个任务有效的表征描述。这对于学习一般的、低级的描述形式、集中模型的注意力或在训练数据有限的环境中特别有用。多任务学习于2008年被Collobert和Weston等人首次在自然语言处理领域应用于神经网络。在他们的模型中,词嵌入矩阵被两个在不同任务下训练的模型共享,共享的词嵌入矩阵使模型可以相互协作。虽然参数的共享是预先定义好的,但在优化的过程中却可以学习不同的共享模式。
通过稀疏向量对文本进行表示的词袋模型,在自然语言处理领域已经有很长的历史了。而用稠密的向量对词语进行描述,也就是词嵌入,则在2001年首次出现。2013年Mikolov等人工作的主要创新之处在于,通过去除隐藏层和近似计算目标使词嵌入模型的训练更为高效。尽管这些改变在本质上是十分简单的,但它们与高效的word2vec(word to vector,用来产生词向量的相关模型)组合在一起,使得大规模的词嵌入模型训练成为可能。Word2vec有两种不同的实现方法:CBOW(continuous bag-of-words)和skip-gram。它们在预测目标上有所不同:一个是根据周围的词语预测中心词语,另一个则恰恰相反。虽然这些嵌入与使用前馈神经网络学习的嵌入在概念上没有区别,但是在一个非常大语料库上的训练使它们能够获取诸如性别、动词时态和国际事务等单词之间的特定关系。这些关系和它们背后的意义激起了人们对词嵌入的兴趣,许多研究都在关注这些线性关系的来源。
序列到序列学习,即使用神经网络将一个序列映射到另一个序列的一般化框架。在这个框架中,一个作为编码器的神经网络对句子符号进行处理,并将其压缩成向量表示;然后,一个作为解码器的神经网络根据编码器的状态逐个预测输出符号,并将前一个预测得到的输出符号作为预测下一个输出符号的输入。机器翻译是这一框架的杀手级应用。谷歌宣布他们将用神经机器翻译模型取代基于短语的整句机器翻译模型。该框架在自然语言生成任务上被广泛应用,其编码器和解码器分别由不同的模型来担任。
注意力机制是神经网络机器翻译(NMT)的核心创新之一,也是使神经网络机器翻译优于经典的基于短语的机器翻译的关键。序列到序列学习的主要瓶颈是,需要将源序列的全部内容压缩为固定大小的向量。注意力机制通过让解码器回顾源序列的隐藏状态,以此为解码器提供加权平均值的输入来缓解这一问题。
注意力机制可以视为模糊记忆的一种形式,其记忆的内容包括模型之前的隐藏状态,由模型选择从记忆中检索哪些内容。与此同时,更多具有明确记忆单元的模型被提出。记忆的存取通常与注意力机制相似,基于与当前状态且可以读取和写入。这些模型之间的差异体现在它们如何实现和利用存储模块。
预训练的词嵌入与上下文无关,仅用于初始化模型中的第一层。近几个月以来,许多有监督的任务被用来预训练神经网络。相比之下,语言模型只需要未标记的文本,因此其训练可以扩展到数十亿单词的语料、新的领域、新的语言。使用预训练的语言模型可以在数据量十分少的情况下有效学习。由于语言模型的训练只需要无标签的数据,因此他们对于数据稀缺的低资源语言特别有利。
结构递归神经网络自下而上构建序列的表示,与从左至右或从右至左对序列进行处理的循环神经网络形成鲜明的对比。树中的每个节点是通过子节点的表征计算得到的。一个树也可以视为在循环神经网络上施加不同的处理顺序,所以长短期记忆网络则可以很容易地被扩展为一棵树。
 微信扫码咨询
微信扫码咨询  相关工具
相关工具
相关文章
相关快讯
推荐

中国首款3A游戏上线,《黑神话:悟空》出圈!
2024-08-21 13:46

盘点15款AI配音工具,短视频配音有救了!
2024-08-12 17:11

短视频文案没创意?10大AI写作工具来帮你!
2024-08-05 16:23

Midjourney发布V6.1版本,我已分不清AI和现实了!
2024-08-01 15:03

我发现了一款国产AI绘画神器,免费易上手!
2024-07-25 16:40
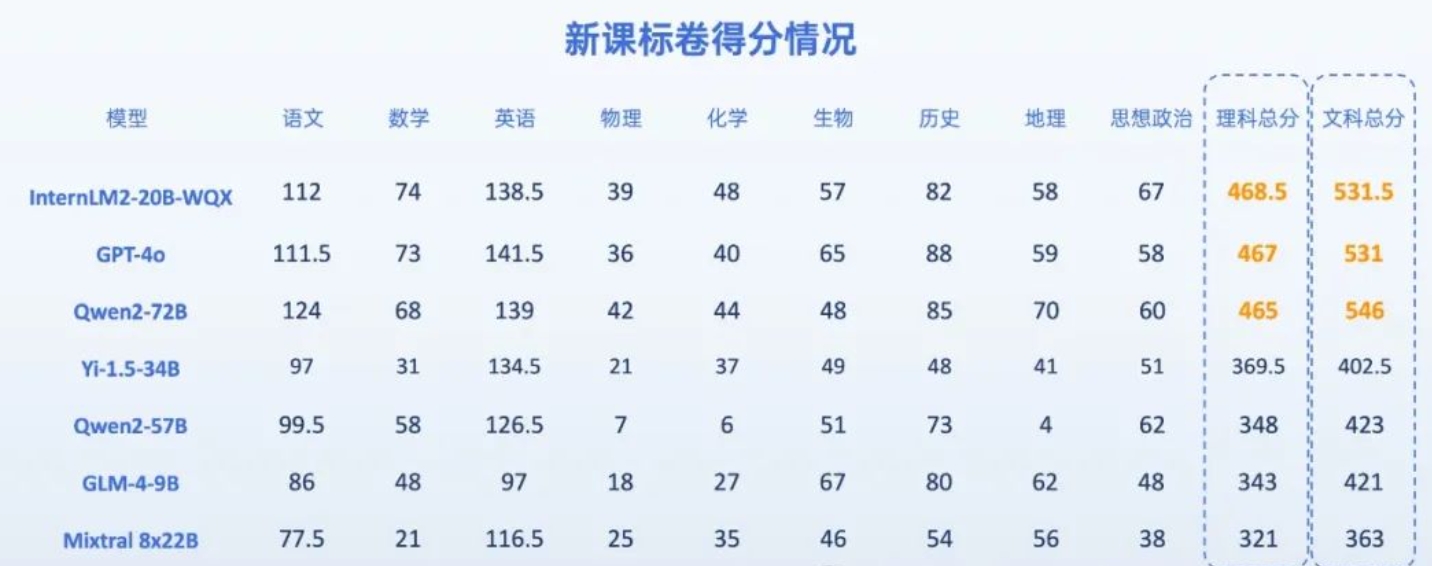
7位AI考生做今年高考题,能过一本线吗?
2024-07-19 17:17

世界上第一所AI学校来了,80亿人只需要1位老师?
2024-07-18 17:12

Sora首部AI广告片上线,广告从业者危险了!
2024-06-27 13:44

OpenAI与中国说拜拜,国产AI如何接棒?
2024-06-26 15:18

人与AI会产生爱情吗,专家发话了!
2024-06-17 17:28
Copyright © 2017-2024 蜀ICP备18012294号-1
成都新知榜文化传播有限公司 版权所有



